Abstract
We introduce a novel problem, i.e., the localization of an input image within a multi-modal reference map represented by a database of 3D scene graphs. These graphs comprise multiple modalities, including object-level point clouds, images, attributes, and relationships between objects, offering a lightweight and efficient alternative to conventional methods that rely on extensive image databases. Given the available modalities, the proposed method SceneGraphLoc learns a fixed-sized embedding for each node (i.e., representing an object instance) in the scene graph, enabling effective matching with the objects visible in the input query image. This strategy significantly outperforms other cross-modal methods, even without incorporating images into the map embeddings. When images are leveraged, SceneGraphLoc achieves performance close to that of state-of-the-art techniques depending on large image databases, while requiring three orders-of-magnitude less storage and operating orders-of-magnitude faster. The code will be made public.
Framework
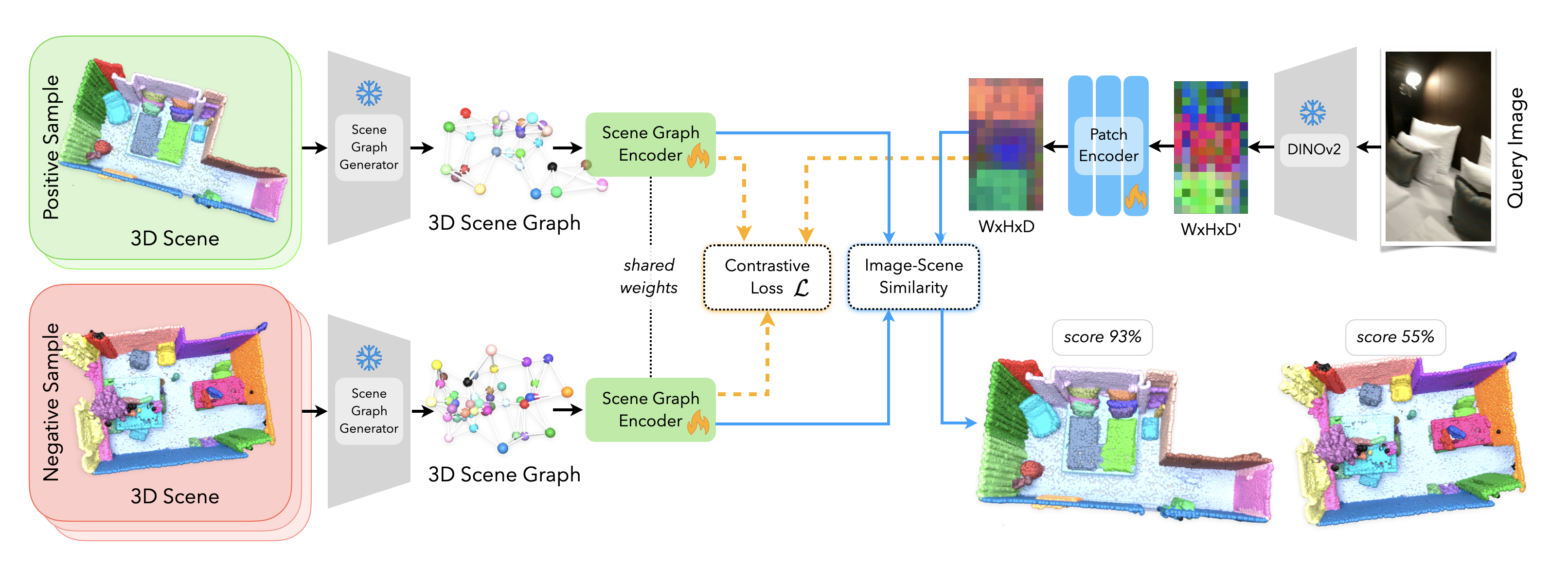
The training phase is represented by orange arrows, while blue arrows denote the inference phase. During training, a query image and its associated 3D scene graph form a positive sample within a contrastive learning framework, where negative samples are generated by associating scene graphs of different scenes with the same query image. The objective is to learn the embeddings of both the graph and the image so that embeddings of the positive pair are drawn closer, whereas those of the negative pair are pushed apart. In the inference phase, the task involves assigning the correct scene graph to a given query image from a selection of multiple graphs, achieved by optimizing the cosine similarity between their embeddings.
Multi-Modal Scene Graph
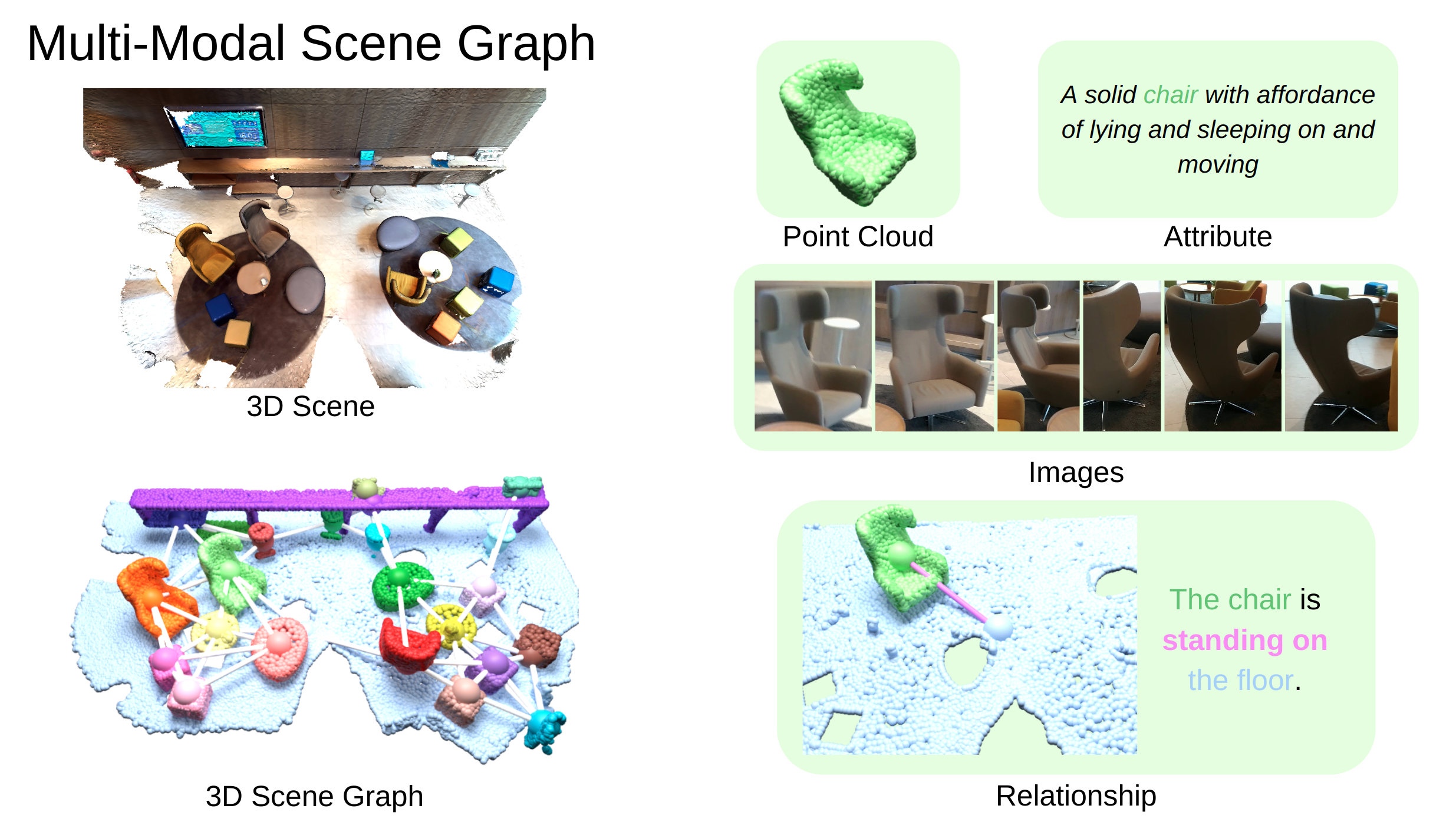
Our method considers the scene graph containing a set of objects as nodes, and their relationships as edges, with modalities including 3D point cloud, 2D images crops and text descriptions of objects, and relationships between them.
Multi-Modal Embedding
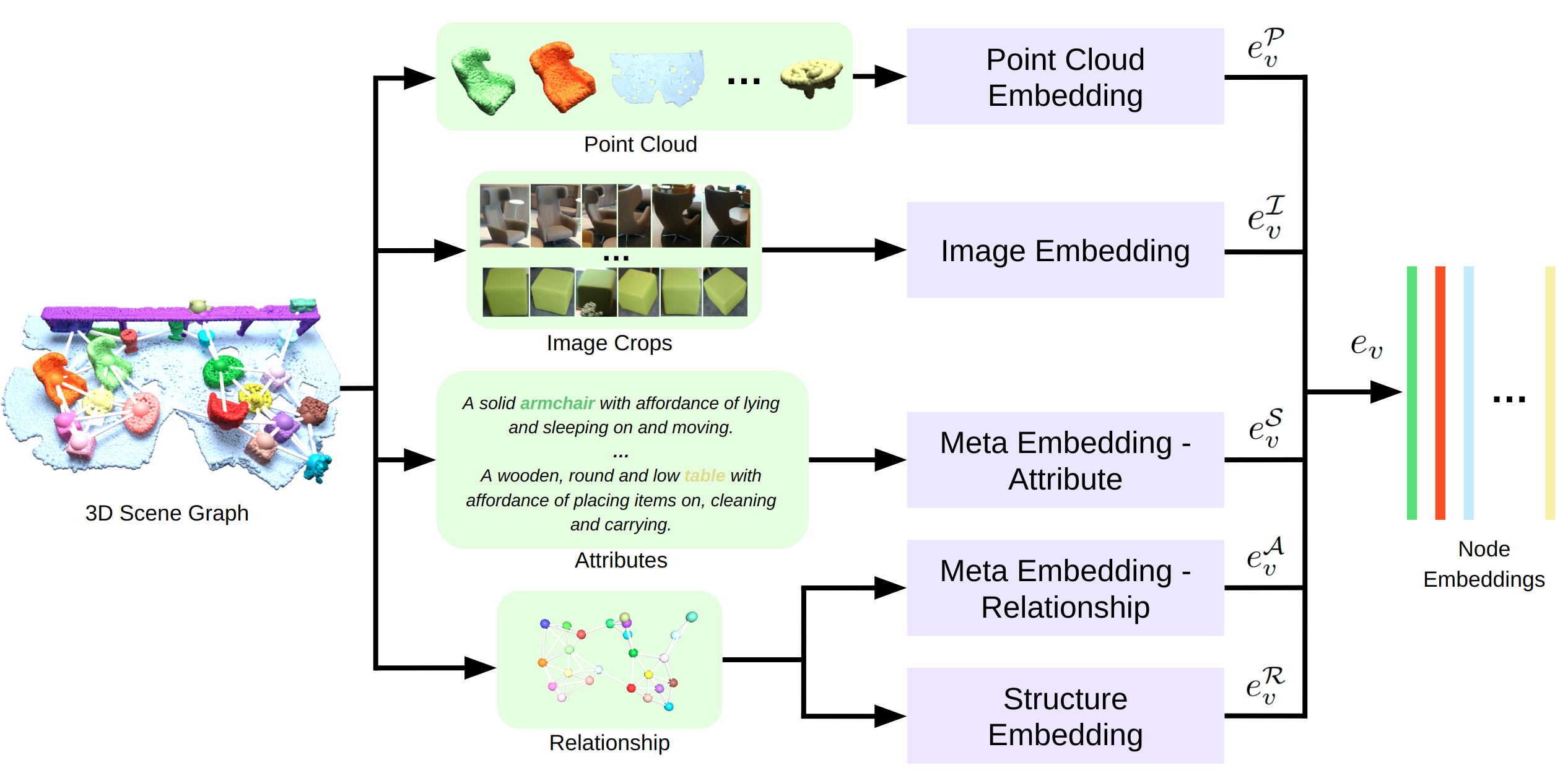
For scene graph embedding, we leverage the rich information of multiple modalities of the 3D scene graph, and encode each modality separately and then fuse them together to get the final unified embedding for each object node.
Qualitative results

By leveraging multi-modal information of the 3D scene graph, we associate patch-object matching between the query image and the objects within the scene graph and calculate image-scene similarity score for scene retrieval.
BibTeX
@inproceedings{miao2024scenegraphloc,
title={{SceneGraphLoc: Cross-Modal Coarse Visual Localization on 3D Scene Graphs}},
author={Miao, Yang and Engelmann, Francis and Vysotska, Olga and Tombari, Federico and Pollefeys, Marc and Bar{\'a}th, D{\'a}niel B{\'e}la},
booktitle=European Conference on Computer Vision (ECCV),
year={2024}
}